这是我第一次写回顾总结性质的文章,真正坐下来开写的时候,才意识到想把一件事物按其历史发展总结展望一下的难度还是蛮大的。
因为明天得做一个组会的 presentation,就想着把我所了解的 embedding 方法给做一个整体性的介绍,希望能够对后续继续入生物序列词嵌入坑的师弟师妹们有所帮助。
文章结构就分成 5 大块,分别为单词级别、句子 / 文档级别、子词级别、字符级别的 embedding 方法,以及最后的总结和展望。
Word-level Embedding
单词级别的 embedding 方法之前就有几篇文章写过了,CS224n Lecture 2,CS224n Lecture 3,CS224n Research Highlight 3。
在此再简单提一下单词级别的 embedding 方法的发展。
传统方式
最初 NLP 领域是靠一个大词典 (例如WordNet) ,所使用的是上位词和同义词集的信息来表示词的意思。但是这种方法忽视了单词的语境,并且很难维护。
NLP 领域还用 One-hot 编码方式来表示词的意思,但是这种方法的缺点也是显而易见的,即无法度量单词之间的相似度、数据稀疏、维度灾难。
稠密词向量
然后 NLP 专家们想出了用稠密的向量来表示一个词的意思,这里需要特别提一下的是一句话
You shall know a word by the company it keeps.
换句话说就是一个词的意思可以由其上下文来表示,这种观点是后续词嵌入模型的根基。
最初模型走的路子大概可以分为两条:直接使用局部上下文信息的方法、基于共现矩阵的方法。
前者的代表为 Word2Vec 算法,后者的代表为 GloVe 算法,具体的内容可以参照以上三篇。
动态方法 ELMo
今年在 NAACL18 上 ELMo 横空出世了,ELMo 词向量的使用把各种 NLP 任务的 state-of-the-art 刷新了一下。
优势
ELMo 的优势如下:
- 能够学习到词汇用法的复杂性,比如语法、语义。
- 能够学习不同上下文情况下的词汇多义性。
与上述的几种方法不同的是,ELMo 所学得的词向量是动态的,在不同的上下文环境中将会得到不同的词向量表达。
定义
ELMo 的思路也是利用单词的上下文信息来表示中心词,与 Word2Vec 等方法简单的线性模型不同的是,ELMo 所用的为 biLSTM 模型,公式如下:
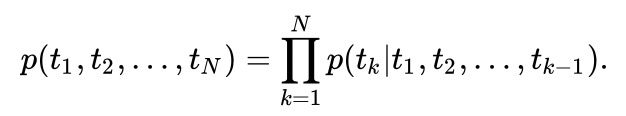
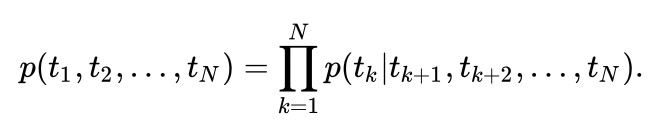
进而最大化其似然函数可得目标函数为: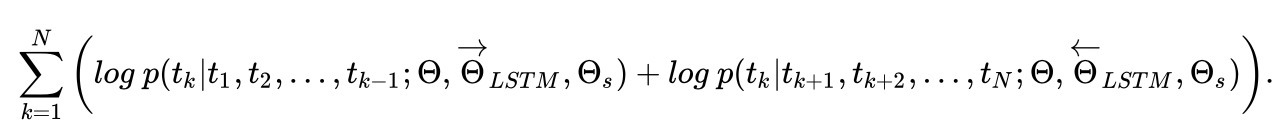
模型细节
ELMo 是双向语言模型 biLM 的多层表示的组合,对于某一个词语 $t_k$,一个 L 层的双向语言模型 biLM 能够由 2L+1 个向量表示。

ELMo 将多层的 biLM 的输出 R 整合成一个向量,$ELMo_k = E(R_k;\theta_e)$。不同层的隐藏状态保留了不同层次的单词信息,一种比较简单的方法是直接拿最顶层的隐藏状态作为词向量,而最好的方法则是将 biLM 层所有层的输出加上一个正则化的 softmax 得到的权重向量。
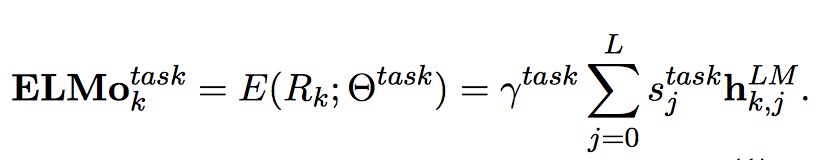
其中 $\gamma$ 是缩放因子,作用类似于 LN。
论文里头没有给出模型图,因为时间关系,我就随便上网扒了一张 ELMo 的模型图,不过我发现这图是有错误的,姑且放上来凑个数。论文中对模型的描述为
The final model uses L = 2 biLSTM layers with 4096 units and 512 dimension projections and a residual connection from the first to second layer.
这里需要说明的是,ELMo 的输入为 char-n-gram embedding,来自 CNN + highway network。
The context insensitive type representation uses 2048 character n-gram convolutional filters followed by two highway layers and a linear projection down to a 512 representation.
作者发现 ELMo 模型如果能够进行适当的 dropout 或者加入 L2 范式的话,可以使得其最终权重保持在各层 biLM 层的权重均值附近。
用法
ELMo 的使用方法也是比较有意思的,有以下两种:
- 直接将 ELMo 词向量与普通词向量拼接。
- 直接将 ELMo 词向量与隐藏变量拼接。
Sentence / Document-level Embedding
在句子和文档层面上,由于句子和文档与单词不同,出现的次数很少,并没有像单词一样预训练出词向量以供使用的必要,而是在特定的 NLP 任务中动态生成。
句子和文档层面的 embedding 方法主要分为两类:无监督方法和有监督方法。
无监督方法
我在之前的 CS224n Research Highligh 1 介绍了一种简单有效的无监督方法。时间关系,这里留一个坑 Skip-thought vectors,Quick-thoughts vectors。
有监督方法
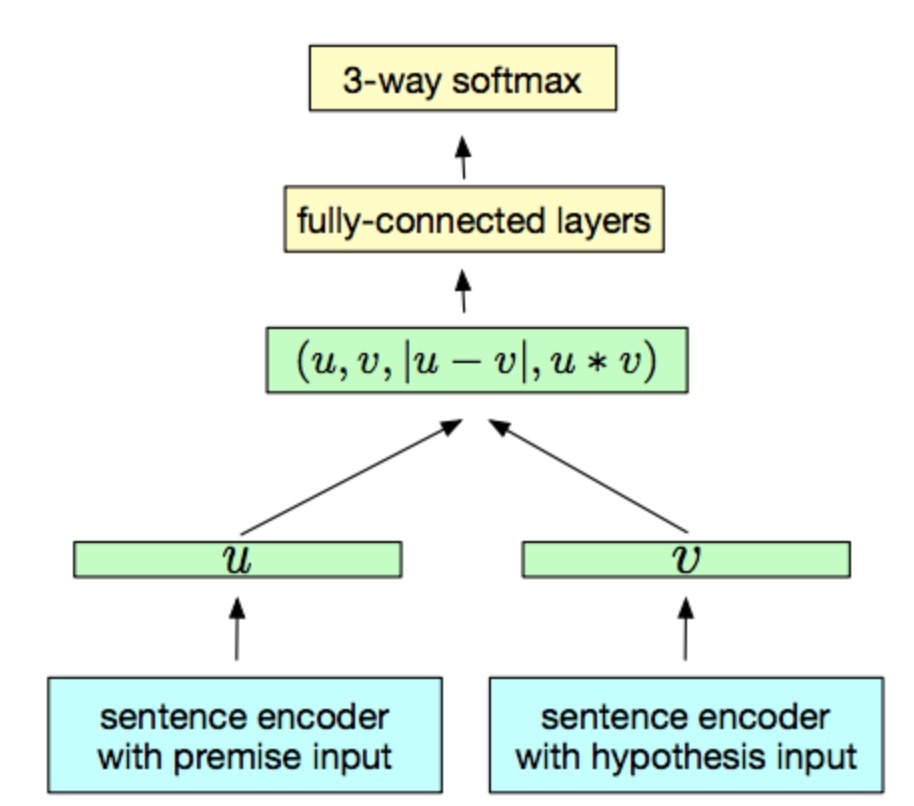
以往的有监督方法只是通过简单的 RNN、CNN 架构来实现,效果往往比无监督方式差,但是最近提出的 InferSent 则取得了非常好的效果,这篇文章是用来做自然语言推导 (NLI) 的,因为之后打算写一篇 NLI 方向的文章,所以这个模型打算放到那边再讲。
InferSent 的模型结构很简单,如下图所示。其编码器由 BiLSTM + max pooling 构成。
Subword-level Embedding
因为一些单词出现


