cs224n 这门课很有意思的一个地方在于教授会让 TA 在中场休息时候花个 5 分钟左右的时间来讲一下当前的研究亮点。我觉得这点很可取,这么做有助于学生开拓思路、紧跟当下热点,可惜这种做法在国内的大学中是很少能够看见。
这个小讲座讲的是发表在 ICLR17 的一篇文章,A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SEN- TENCE EMBEDDINGS。
动机
本文是用无监督方法做句子级别的 embedding,用的是一个十分简单但却又很有效的传统方法,这在神经网络泛滥的年代算是一股清流了。
作者做 word2sen 的动机是想要得到句子的词向量,这样就可以进行句子间的相似度计算了。除此之外,还能在这些句向量的基础上构建分类器来做情感分析的研究。


已有方法
稍微介绍一下目前已有的方法。
基于无监督的线性变换的方法。例如简单的对词向量求平均,或者对词向量进行加权平均 (例如以 TF-IDF 为权值)。

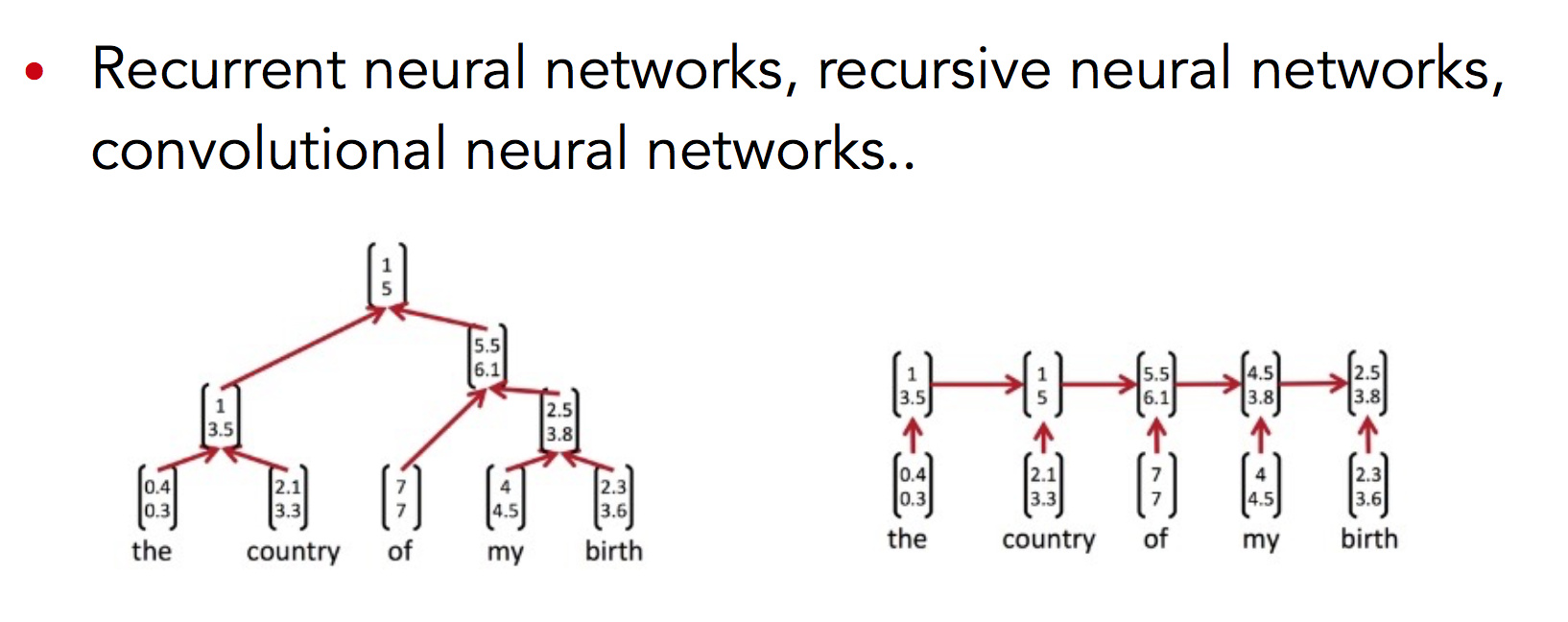
基于有监督的神经网络的方法。例如各种满天乱飞的 CNN, RNN (Recurrent), RNN (Recursive) 模型得到的句向量。
本文方法
作者将该算法称为 WR,W 表示 Weighted,根据预设的超参数和词频给每个词向量赋予权重。R 表示 Removal,使用PCA移除句向量中的无关部分。

算法流程分为两步:
- W 步:对于句子中的每个词向量乘以一个独特的权值,即 $\frac{a}{a+p(w)}$,其中 $a$ 为一个常数 (论文中建议 $a$ 的范围: [$1e−4,1e−3$] ), $p(w)$ 为该词的频率。
- R 步:计算语料库所有句向量构成的矩阵的第一个主成分 $u$,让每个句向量减去它在 $u$ 上的投影 (类似 PCA)。其中,一个向量 $v$ 在另一个向量 $u$ 上的投影定义为:$Proj_uv = \frac{uu^Tv}{||u||^2}$。
概率论解释
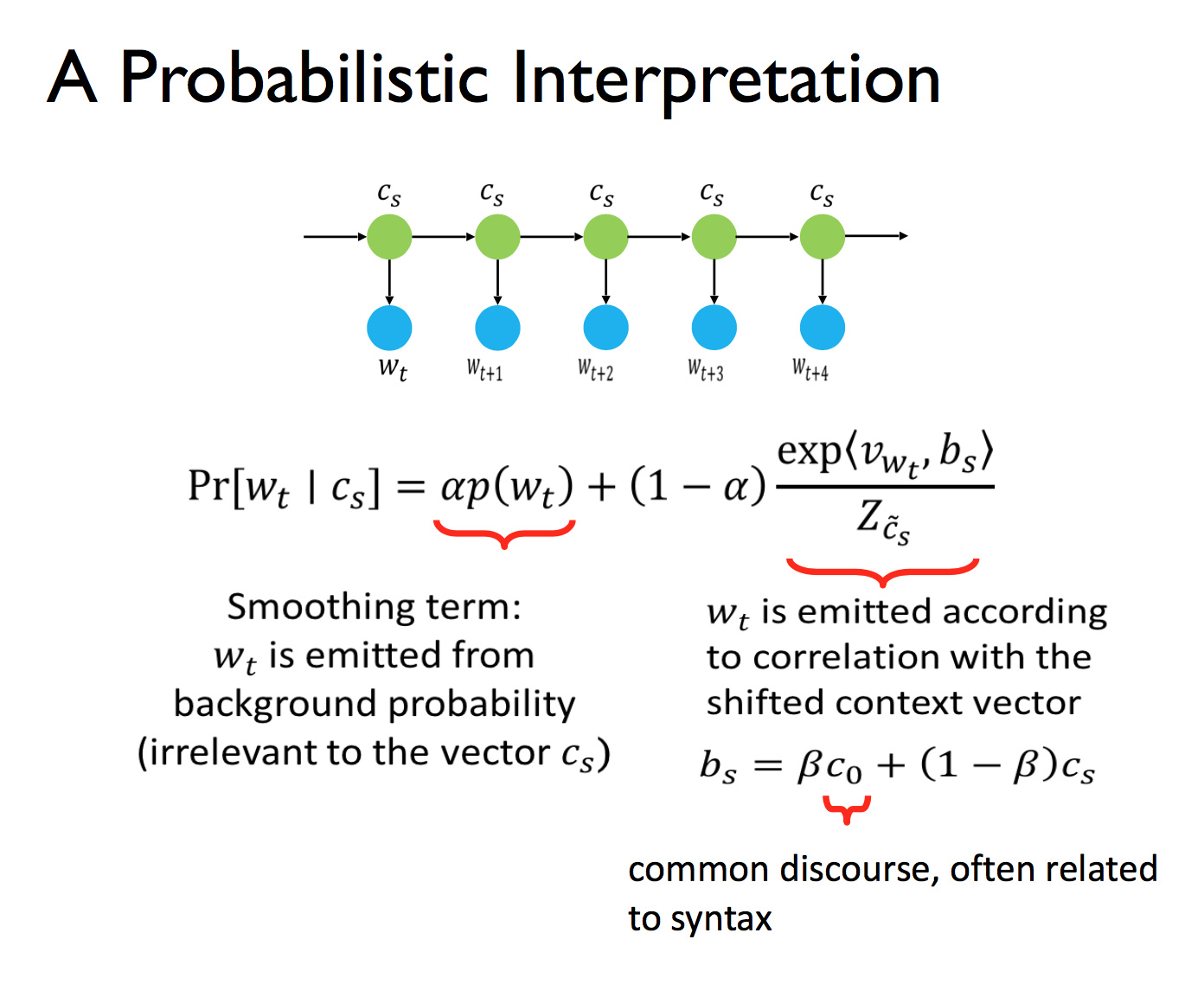
其原理是,给定上下文向量,一个词的出现概率由两项决定:作为平滑项的词频,以及上下文。其中第二项的意思是,有一个平滑变动的上下文随机地发射单词。
这篇文章我没有看过原文,这里其实并不是完全理解,等之后再来填坑。
结果
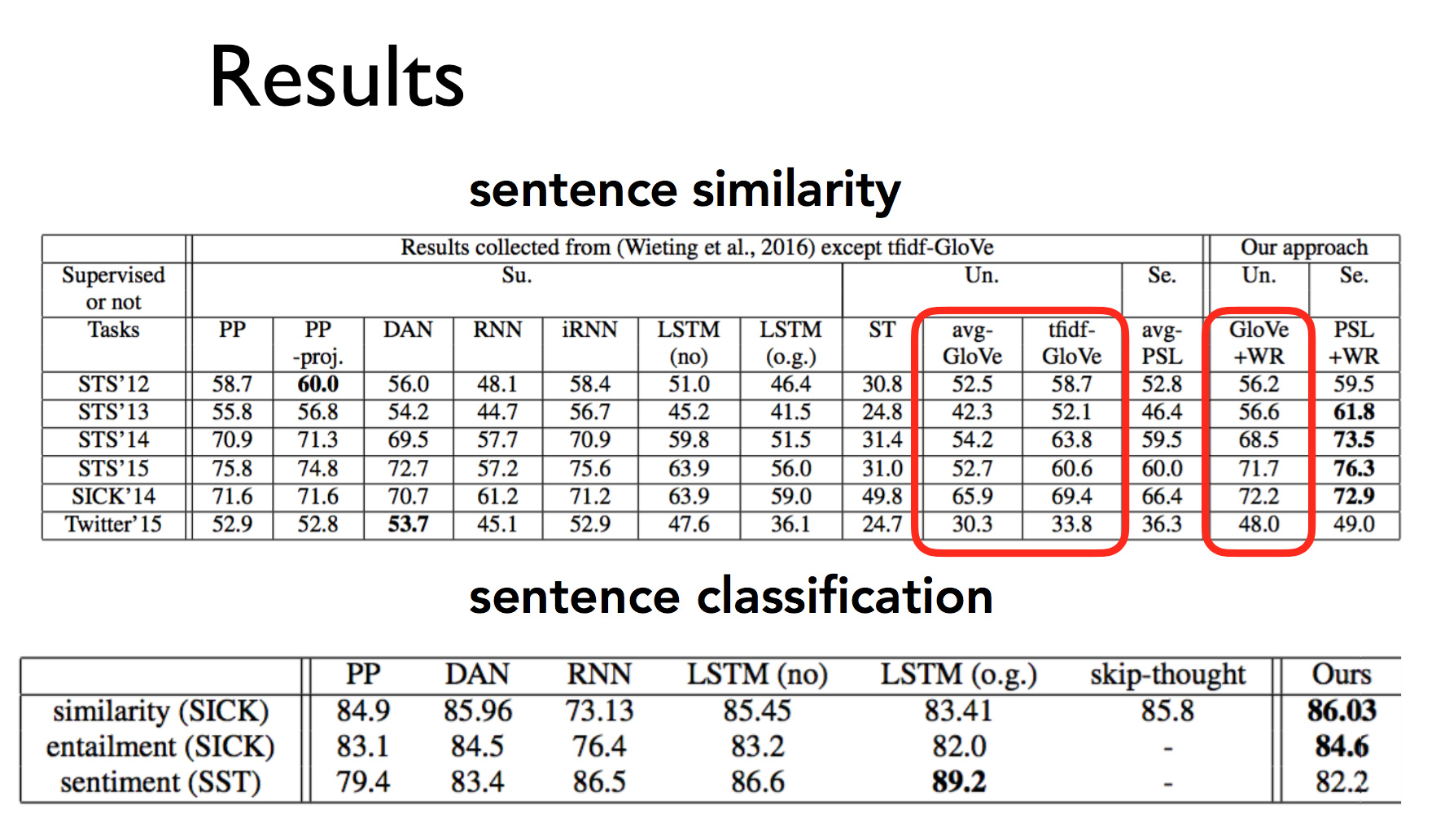
取得了一个不错的结果,但是比 LSTM 效果好这种说法不太妥当,这得取决于实际的任务。
不过无论如何,这种方法运行耗时短,结果又不错,可以当做一个很好的 baseline。


