这是我第一次写回顾总结性质的文章,真正坐下来开写的时候,才意识到想把一件事物按其历史发展总结展望一下的难度还是蛮大的。
因为明天得做一个组会的 presentation,就想着把我所了解的 embedding 方法给做一个整体性的介绍,希望能够对后续继续入生物序列词嵌入坑的师弟师妹们有所帮助。
文章结构就分成 5 大块,分别为单词级别、句子 / 文档级别、子词级别、字符级别的 embedding 方法,以及最后的总结和展望。
Word-level Embedding
单词级别的 embedding 方法之前就有几篇文章写过了,CS224n Lecture 2,CS224n Lecture 3,CS224n Research Highlight 3。
在此再简单提一下单词级别的 embedding 方法的发展。
传统方式
- 基于分类:最初 NLP 领域是靠一个大词典 (例如WordNet) ,所使用的是上位词和同义词集的信息将单词归到不同的类别中去,以此来表示单词的意思。但是这种方法忽视了单词的语境,并且很难维护。
- 离散编码:NLP 领域还用 One-hot 编码方式来表示词的意思,但是这种方法的缺点也是显而易见的,即无法度量单词之间的相似度、数据稀疏、维度灾难。
稠密词向量
然后 NLP 专家们想出了用稠密的向量来表示一个词的意思,这里需要特别提一下的是一句话
You shall know a word by the company it keeps.
换句话说就是一个词的意思可以由其上下文来表示,这种观点是后续词嵌入模型的根基。
最初模型走的路子大概可以分为两条:直接使用局部上下文信息的方法、基于共现矩阵的方法。
前者的代表为 Word2Vec 算法,后者的代表为 GloVe 算法,具体的内容可以参照以上三篇。
动态方法
今年在 NAACL18 上 ELMo 横空出世了,ELMo 词向量的使用把各种 NLP 任务的 state-of-the-art 刷新了一下。
优势
ELMo 的优势如下:
- 能够学习到词汇用法的复杂性,比如语法、语义。
- 能够学习不同上下文情况下的词汇多义性。
与上述的几种方法不同的是,ELMo 所学得的词向量是动态的,在不同的上下文环境中将会得到不同的词向量表达。
定义
ELMo 的思路也是利用单词的上下文信息来表示中心词,与 Word2Vec 等方法简单的线性模型不同的是,ELMo 所用的为 biLSTM 模型,公式如下:
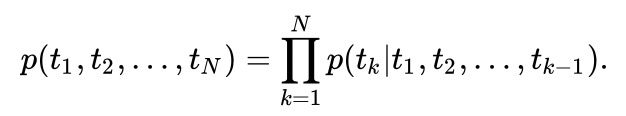
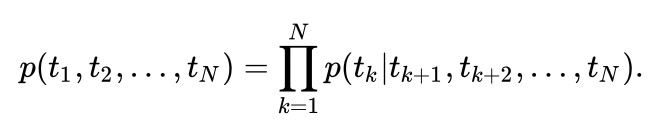
进而最大化其似然函数可得目标函数为: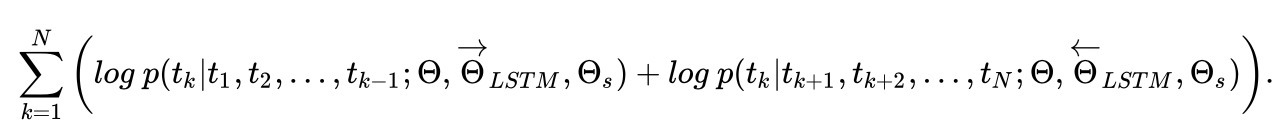
模型细节
ELMo 是双向语言模型 biLM 的多层表示的组合,对于某一个词语 $t_k$,一个 L 层的双向语言模型 biLM 能够由 2L+1 个向量表示。

ELMo 将多层的 biLM 的输出 $R$ 整合成一个向量,$ELMo_k = E(R_k; \theta_e)$。不同层的隐藏状态保留了不同层次的单词信息,一种比较简单的方法是直接拿最顶层的隐藏状态作为词向量,而最好的方法则是将 biLM 层所有层的输出加上一个正则化的 softmax 得到的权重向量。
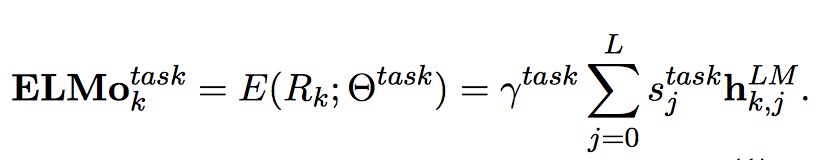
其中 $\gamma$ 是缩放因子,作用类似于 LN。
论文里头没有给出模型图,因为时间关系,我就随便上网扒了一张 ELMo 的模型图,不过我发现这图是有错误的,姑且放上来凑个数。论文中对模型的描述为
The final model uses L = 2 biLSTM layers with 4096 units and 512 dimension projections and a residual connection from the first to second layer.
这里需要说明的是,ELMo 的输入为 char-n-gram embedding,来自 CNN + highway network。
The context insensitive type representation uses 2048 character n-gram convolutional filters followed by two highway layers and a linear projection down to a 512 representation.
作者发现 ELMo 模型如果能够进行适当的 dropout 或者加入 L2 范式的话,可以使得其最终权重保持在各层 biLM 层的权重均值附近。
用法
ELMo 的使用方法也是比较有意思的,有以下两种:
- 直接将 ELMo 词向量与普通词向量拼接。
- 直接将 ELMo 词向量与隐藏变量拼接。
补充一下:讲完组会后当天下午看到机器之心推送 NLP领域的ImageNet时代到来:词嵌入「已死」,语言模型当立。标题一看就想搞个大新闻,虽然是一股浓浓的传销性质的标题党文章,但不得不承认 ELMo 这类模型思想和用法确实算是开辟了词嵌入的另一条路,NLP 的迁移学习时代可能真的不远了。
Sentence / Document-level Embedding
在句子和文档层面上,由于句子和文档与单词不同,出现的次数很少,并没有像单词一样预训练出词向量以供使用的必要,而是在特定的 NLP 任务中动态生成。
句子和文档层面的 embedding 方法主要分为两类:无监督方法和有监督方法。
无监督方法
我在之前的 CS224n Research Highligh 1 介绍了一种简单有效的无监督方法,这里再介绍一下另一篇文章 Distributed Representations of Sentences and Documents。
这篇文章还是 Mikolov 老爷子的作品,所以模型框架跟 Word2Vec 以及 fastText 很相似,所以同样就大概讲一下模型思想。这篇文章分别介绍了句向量和段落向量的表征方式:
句向量
对于句向量的训练,本文的做法只是在 Word2Vec 的基础上做延伸工作。本文将得到单词的词向量做简单的求均值或者拼接获得句向量,并且直接根据实际任务来做个分类,在训练任务分类器的过程中同样取得了句向量的表示。这种思想已经有点 fastText 的雏形了,模型的架构图如下:
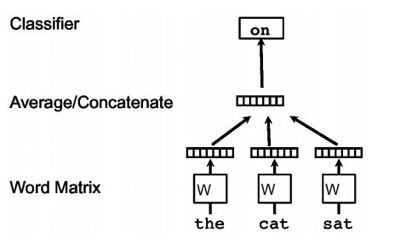
段落向量
关于段落向量的训练,本文提出了两种方法,这里主要介绍一下第一种,即 PV-DM。PV-DM 也是一样的套路,唯一的区别是输入端加入了一个表示段落 id 的 token。该算法主要分为两个阶段:
- 在训练阶段,我们先学得了模型的参数。
- 而在预测阶段,随机初始化一个新的段落向量,即目标段落向量。然后将步骤 1 中学得的模型参数给固定住,以同样的方式来训练得出新的段落向量。
作者的观点是借由这个段落向量,我们可以更好地保留住普通词向量所不能包含的特定语境下面的上下文信息,相当于我们多保留了一个该语境下的额外信息。PV-DM 的模型架构图如下所示:
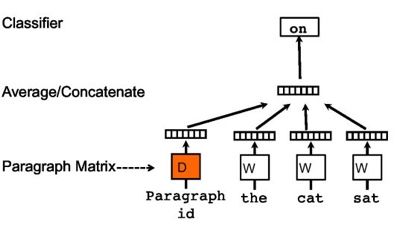
至于 PV-DBOW 架构,跟 Word2Vec 里头的 Skip-gram 模型很相近,思想是拿段落 id 来对相应的上下文信息进行拟合,最终同样可以得到段落向量。但个人认为这种方法很不靠谱,纯粹地拿段落的 id 当作输入来拟合上下文的单词,损失掉了包括词序在内的很多信息。PV-DBOW 的模型架构图如下所示:
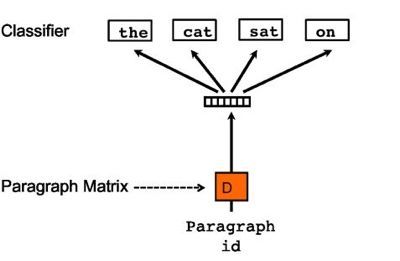
因时间关系来不及看另外两篇比较出名的文章,这里留一个坑 Skip-thought vectors,Quick-thoughts vectors,日后了解了这两种模型思想后再来填土。
有监督方法
以往的有监督方法只是通过简单的 RNN、CNN 架构来实现,效果往往比无监督方式差,但是最近提出的 InferSent 则取得了非常好的效果,这篇文章是用来做自然语言推导 (NLI) 的,因为之后打算写一篇 NLI 方向的文章,所以这个模型打算放到那边再细讲。(后续补充:InferSent 的模型介绍 )
InferSent 的模型结构很简单,如下图所示。其编码器由 BiLSTM + max pooling 构成。
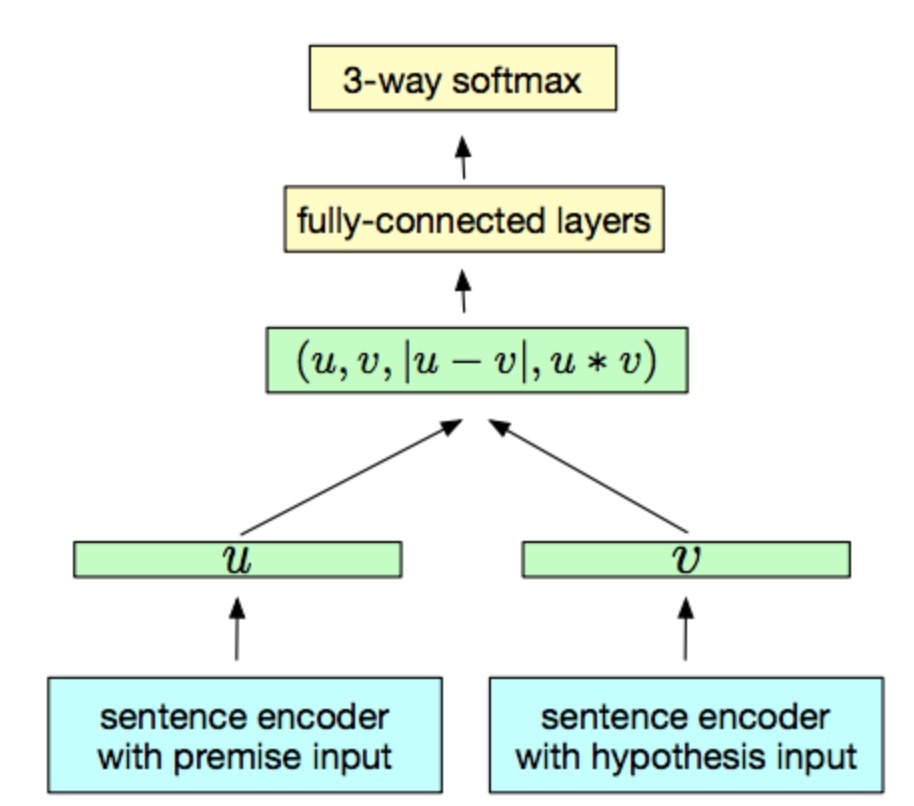
Subword-level Embedding
最早提出 Subword 这个 embedding 思路的应该是 FAIR 的大佬们的 Enriching Word Vectors with Subword Information 这篇文章。
Subword 是 Word 和 Char 之间的一个中间层,考虑的是从形态学的角度来对词的含义进行表征。这里考虑到了几个 word embedding 方法的不足,比如:
- 在训练词向量的时候,如果某个 word 出现的次数比较少的话,那么它的更新次数也会较少,这样就很难学到这个 word 的高质量的向量表示。
- 有些词过于稀有,没有在预训练词向量的语料中出现,这样就会导致预测结果无法得到这个词。这里以人名举个例子,假设我们在做阅读理解,”His name is Mikolov, …, __ is a NLP expert. “ 我们一整段话都说对 Mikolov 大神的描述,最后留个空格要填入 Mikolov,然而由于这个姓氏太过于稀有,没有在训练语料中出现,所以模型无论如何也得不到正确答案。
- 单词的构成可能会包含一些前缀和后缀的信息 (e.g. pre-, sub-, -un, -er, -est)。单词的构成也可能是由不同的成分组合而成的 (e.g. bio + informatics)。这些信息在一定程度上也能够表示单词的含义,然而在 word-level 的 embedding 中,这些信息往往会被忽略掉了。
而 Subword embedding 的提出则能很好地解决上述的问题,在此介绍一下两种比较常见的 subword-level embedding 的方法:
##N-gram
顾名思义,就是以一个固定长度的滑动窗口去对单词的子词进行截取[e.g. apple -> (ap, app, ppl, ple, le)],最后将各个 subword 的向量求和即可得到整个 word 的向量表示。上述提及的 Enriching Word Vectors with Subword Information 用的就是 n-gram 的方法,在训练时候就是用中心词的 n-gram embedding 来预测目标词。
##BPE
BPE 算法其实是 94 年 Gage 等人提出的,但是 Neural Machine Translation of Rare Words with Subword Unitz 这篇 nmt 文章将其用到了 subword-level 上来。我们可以知道 n-gram 方法虽然能够解决上述的 word-level embedding 的问题,但是它由于是滑动窗口采样的,会导致存在大量冗余信息,也会导致词表大小增大导致算法运行效率变慢。那么如果我们可以对常用词采用 word-level 向量的表示,稀有词再用 subword-level 向量的表示,则可以很好地解决上述问题,因此作者提出用 subword-level 的 BPE 算法来解决这个问题。
BPE 算法的思想其实就是,首先将各个单字符初始化为 token,再统计一下两两相邻 token 的出现次数,将次数最大的 token pair 给合并起来成为新的 token,放回继续统计和合并,最终得到非重叠的 subword。
经过这种组合方式后,常见词最终会由 char 回归到 word 级别,而稀有词则会在 subword 层面上就停止了合并,也就达到了我们的目的。比如 unoffical 就是一个稀有词,而 un 和 offical 则会在语料中大量出现,因而通过 BPE 这种方法,我们最终可以将 unoffical 拆成 un + offical 的组合,进而得到高质量的词向量表示。
Char-level Embedding
前面介绍了那么多 -level 的 embedding 方法,最终人们发现,其实最初的 char-level 的词向量也足以很好地完成很多任务了。除此之外,char-level embedding 还可以当做 word-level embedding 的补充来配合使用。
常见的 char-level embedding 只是由 CNN / RNN / RNN-LM 构成。而 Character-Aware Neural Language Models 则提出了 CNN + Highway 的框架,能够很好地捕获 char-level 的信息。因为之前组会上 张开明 刚讲过这个模型在推荐系统上面的应用,所以就不继续讲这个模型了,模型图如下所示:
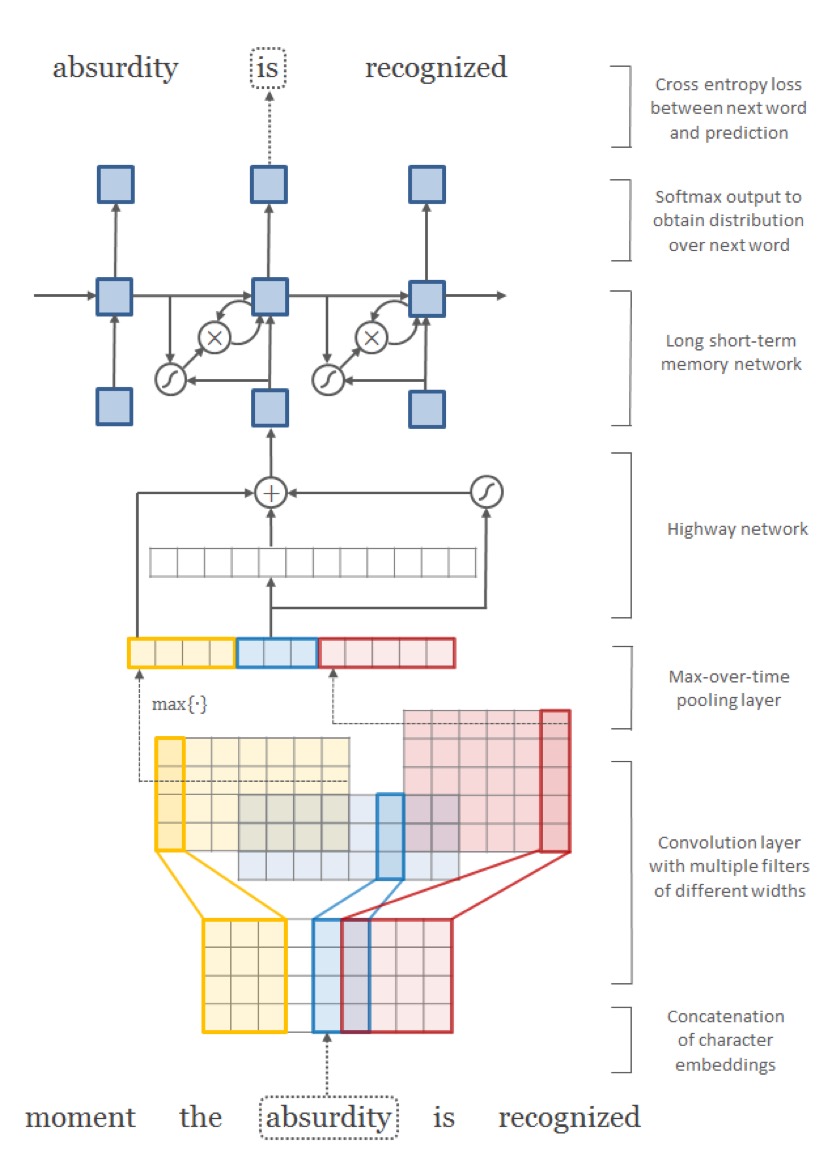
展望
也算把各个层面的 embedding 方法总结了一下了,其实我还看了几年前的几篇关于 embedding 的文章,分别是李嫣然女神的 “后 Word Embedding ”的热点会在哪里? 和 Adapations and Variations of Word2vec,以及 licstar 的 《How to Generate a Good Word Embedding?》导读 和 Deep Learning in NLP (一)词向量和语言模型。
现在在 18 年回头看 “后 Word Embedding ”的热点会在哪里? 这篇文章,会发现当初李嫣然提及的四个方向都有所验证:
- Interpretable relations : 虽然可解释性上目前做得还不够好,但是从形态学方面去入手的研究以及有很多了,比如上文提及的 subword-level, character-level 的研究。
- Lexical resources : 虽然训练的词向量可以表示词汇的关系了,但是如果能够再将人工标注的词汇资源加入进去,对于词向量的质量是不是有所提升呢?
- Beyond words : 这个就更好理解了,将 embedding 的范围扩大到 sentence 、 paragraph 甚至 document 的层面上去。
- Beyond English : 英语作为一种通用语言,所能够获取的训练语料真的十分丰富,而接下来的研究就该转向到那些其他语种的 embedding 中去了。
诚然,时至今日,虽然这一两年还是有 EMLo, InferSent 这些方法的出现,但是 embedding 已经算是一个过气的研究方向了。不过在于生物信息学的方向,对于生物序列 (DNA / RNA / Protein) 的 embedding 工作才刚刚展开,这里涉及到了语料、序列长度、序列切割、无监督分词等一系列的难题,但有理由相信,如果能够加入一些额外的生物信息,在有监督的环境下,还是可能获得一个高质量的序列向量的,届时可能会把目前学界对于生物序列的研究给完全革新一遍,这可能是一项很了不起的贡献。
[虽然我做了那么久的无监督序列分词,至今也没有取得什么好结果,但也只能继续安利师弟师妹们继续踩进这个坑里了,毕竟改变世界的梦想还是要有的。:-)
另外由于本人水平有限,这也是我第一次做如此大规模的总结,如果有写错的地方,希望各位大佬们不吝指教。]
参考文献
- 深度 | 当前最好的词句嵌入技术概览:从无监督学习转向监督、多任务学习
- ELMo
- ELMo 最好用的词向量《Deep Contextualized Word Representations》
- PV-DM & PV-DBOW
- Skip-thought vectors
- Quick-thoughts vectors
- InferSent
- Enriching Word Vectors with Subword Information
- Neural Machine Translation of Rare Words with Subword Unitz
- Highway
- “后 Word Embedding ”的热点会在哪里?
- Adapations and Variations of Word2vec
- 《How to Generate a Good Word Embedding?》导读
- Deep Learning in NLP (一)词向量和语言模型


