讲讲最近的实习经历,也算是如愿半路出家跳入 NLP 坑里来了。
背景介绍
来到携程这边后 leader 丢给我三个选项:游记与产品关联并推荐、矛盾条款分析 以及 KBQA。各方面考虑再三后,我选择了矛盾条款分析,实际上也就是 NLI 任务的简化。
矛盾条款分析是属于公司一个叫照妖镜项目下的子任务。相关商家可以把自家的产品发布到携程相关的产品页面上来,照妖镜的功能就是实时地去检查商家发布的产品是否合规,是否有效,如果产品有问题的话 (违规、失去时效) 就将其自动下架甚至对商家进行惩罚。
而矛盾条款分析就是针对商家发布的产品的参与规则进行分析,看其条款是否互相矛盾。举个例子,比如商品参与规则中的其中一条写着“本产品一价全包,后续无需其它费用”,而另一条则写着“本产品不包含 xx 景点门票费用,如欲游览需要自行买票”。那这样这两条条款就是互相矛盾的了,需要模型判断出来并对商家进行惩罚或者下架。
NLI 任务与研究进展
以上所描述的矛盾条款分析任务其实就是 NLI 文本蕴含 (Text Entailment) 任务的简化,它的任务形式为:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,我们需要做的是去发掘前提和假设这两个句子对之间的交互信息。
NLI 任务比较常用的标准数据集为 SNLI (The Stanford Natural Language Inference corpus) 和 MultiNLI (The Multi-Genre Natural Language Inference corpus)。后来 Kaggle 上面又出了一个很出名的比赛,Quora Question Pairs,它做的只是判断 Quora 上的两个问题句是否表示的是一样的意思。
个人而言,我很喜欢 SNLI 这个数据集,并不是因为它最早出现,而是其网站上列出了当前的研究进展、之前在这个任务上的一些经典做法。跟着这张表去刷论文能够让你的学习效率提高很多,反正对于我这种半路出家的人而言,这张表对我的帮助非常大,在接下来写的内容也大部分来自这张表所提及的文章中。
| Publication | Model | Parameters | Train (% acc) | Test (% acc) |
|---|---|---|---|---|
| Feature-based models | ||||
| Bowman et al. ‘15 | Unlexicalized features | 49.4 | 50.4 | |
| Bowman et al. ‘15 | + Unigram and bigram features | 99.7 | 78.2 | |
| Sentence encoding-based models | ||||
| Bowman et al. ‘15 | 100D LSTM encoders | 220k | 84.8 | 77.6 |
| Bowman et al. ‘16 | 300D LSTM encoders | 3.0m | 83.9 | 80.6 |
| Vendrov et al. ‘15 | 1024D GRU encoders w/ unsupervised ‘skip-thoughts’ pre-training | 15m | 98.8 | 81.4 |
| Mou et al. ‘15 | 300D Tree-based CNN encoders | 3.5m | 83.3 | 82.1 |
| Bowman et al. ‘16 | 300D SPINN-PI encoders | 3.7m | 89.2 | 83.2 |
| Yang Liu et al. ‘16 | 600D (300+300) BiLSTM encoders | 2.0m | 86.4 | 83.3 |
| Munkhdalai & Yu ‘16b | 300D NTI-SLSTM-LSTM encoders | 4.0m | 82.5 | 83.4 |
| Yang Liu et al. ‘16 | 600D (300+300) BiLSTM encoders with intra-attention | 2.8m | 84.5 | 84.2 |
| Conneau et al. ‘17 | 4096D BiLSTM with max-pooling | 40m | 85.6 | 84.5 |
| Munkhdalai & Yu ‘16a | 300D NSE encoders | 3.0m | 86.2 | 84.6 |
| Qian Chen et al. ‘17 | 600D (300+300) Deep Gated Attn. BiLSTM encoders (code) | 12m | 90.5 | 85.5 |
| Tao Shen et al. ‘17 | 300D Directional self-attention network encoders (code) | 2.4m | 91.1 | 85.6 |
| Jihun Choi et al. ‘17 | 300D Gumbel TreeLSTM encoders | 2.9m | 91.2 | 85.6 |
| Nie and Bansal ‘17 | 300D Residual stacked encoders | 9.7m | 89.8 | 85.7 |
| Anonymous ‘18 | 1200D REGMAPR (Base+Reg) | – | – | 85.9 |
| Yi Tay et al. ‘18 | 300D CAFE (no cross-sentence attention) | 3.7m | 87.3 | 85.9 |
| Jihun Choi et al. ‘17 | 600D Gumbel TreeLSTM encoders | 10m | 93.1 | 86.0 |
| Nie and Bansal ‘17 | 600D Residual stacked encoders | 29m | 91.0 | 86.0 |
| Tao Shen et al. ‘18 | 300D Reinforced Self-Attention Network | 3.1m | 92.6 | 86.3 |
| Im and Cho ‘17 | Distance-based Self-Attention Network | 4.7m | 89.6 | 86.3 |
| Seonhoon Kim et al. ‘18 | Densely-Connected Recurrent and Co-Attentive Network (encoder) | 5.6m | 91.4 | 86.5 |
| Qian Chen et al. ‘18 | 600D BiLSTM with generalized pooling | 65m | 94.9 | 86.6 |
| Other neural network models | ||||
| Rocktäschel et al. ‘15 | 100D LSTMs w/ word-by-word attention | 250k | 85.3 | 83.5 |
| Pengfei Liu et al. ‘16a | 100D DF-LSTM | 320k | 85.2 | 84.6 |
| Yang Liu et al. ‘16 | 600D (300+300) BiLSTM encoders with intra-attention and symbolic preproc. | 2.8m | 85.9 | 85.0 |
| Pengfei Liu et al. ‘16b | 50D stacked TC-LSTMs | 190k | 86.7 | 85.1 |
| Munkhdalai & Yu ‘16a | 300D MMA-NSE encoders with attention | 3.2m | 86.9 | 85.4 |
| Wang & Jiang ‘15 | 300D mLSTM word-by-word attention model | 1.9m | 92.0 | |
| Jianpeng Cheng et al. ‘16 | 300D LSTMN with deep attention fusion | 1.7m | 87.3 | 85.7 |
| Jianpeng Cheng et al. ‘16 | 450D LSTMN with deep attention fusion | 3.4m | 88.5 | 86.3 |
| Parikh et al. ‘16 | 200D decomposable attention model | 380k | 89.5 | 86.3 |
| Parikh et al. ‘16 | 200D decomposable attention model with intra-sentence attention | 580k | 90.5 | 86.8 |
| Munkhdalai & Yu ‘16b | 300D Full tree matching NTI-SLSTM-LSTM w/ global attention | 3.2m | 88.5 | 87.3 |
| Zhiguo Wang et al. ‘17 | BiMPM | 1.6m | 90.9 | 87.5 |
| Lei Sha et al. ‘16 | 300D re-read LSTM | 2.0m | 90.7 | 87.5 |
| Yichen Gong et al. ‘17 | 448D Densely Interactive Inference Network (DIIN, code) | 4.4m | 91.2 | 88.0 |
| McCann et al. ‘17 | Biattentive Classification Network + CoVe + Char | 22m | 88.5 | 88.1 |
| Chuanqi Tan et al. ‘18 | 150D Multiway Attention Network | 14m | 94.5 | 88.3 |
| Xiaodong Liu et al. ‘18 | Stochastic Answer Network | 3.5m | 93.3 | 88.5 |
| Ghaeini et al. ‘18 | 450D DR-BiLSTM | 7.5m | 94.1 | 88.5 |
| Yi Tay et al. ‘18 | 300D CAFE | 4.7m | 89.8 | 88.5 |
| Qian Chen et al. ‘17 | KIM | 4.3m | 94.1 | 88.6 |
| Qian Chen et al. ‘16 | 600D ESIM + 300D Syntactic TreeLSTM (code) | 7.7m | 93.5 | 88.6 |
| Peters et al. ‘18 | ESIM + ELMo | 8.0m | 91.6 | 88.7 |
| Boyuan Pan et al. ‘18 | 300D DMAN | 9.2m | 95.4 | 88.8 |
| Zhiguo Wang et al. ‘17 | BiMPM Ensemble | 6.4m | 93.2 | 88.8 |
| Yichen Gong et al. ‘17 | 448D Densely Interactive Inference Network (DIIN, code) Ensemble | 17m | 92.3 | 88.9 |
| Seonhoon Kim et al. ‘18 | Densely-Connected Recurrent and Co-Attentive Network | 6.7m | 93.1 | 88.9 |
| Qian Chen et al. ‘17 | KIM Ensemble | 43m | 93.6 | 89.1 |
| Ghaeini et al. ‘18 | 450D DR-BiLSTM Ensemble | 45m | 94.8 | 89.3 |
| Peters et al. ‘18 | ESIM + ELMo Ensemble | 40m | 92.1 | 89.3 |
| Yi Tay et al. ‘18 | 300D CAFE Ensemble | 17.5m | 92.5 | 89.3 |
| Chuanqi Tan et al. ‘18 | 150D Multiway Attention Network Ensemble | 58m | 95.5 | 89.4 |
| Boyuan Pan et al. ‘18 | 300D DMAN Ensemble | 79m | 96.1 | 89.6 |
| Radford et al. ‘18 | Fine-Tuned LM-Pretrained Transformer | 85m | 96.6 | 89.9 |
| Seonhoon Kim et al. ‘18 | Densely-Connected Recurrent and Co-Attentive Network Ensemble | 53.3m | 95.0 | 90.1 |
模型架构
由上图可以看出,NLI 任务的模型被分成了三类,Feature-based models, Sentence encoding-based models, Other neural network models。下面的内容就是从上面的内容中挑出来的几篇比较经典的文章。(说这么好听,其实也就是我最近做矛盾条款这个项目刷过的论文,逃)
Feature-based models
表中的 Feature-based 的方法其实就只涉及了一篇文章,A large annotated corpus for learning natural language inference。这篇文章发表在了 EMNLP2015,也正是这篇文章公开了 SNLI 这个标准数据集。文中其实对 Feature-based 和 Sentence encoding-based 的方法都有介绍,由于小节标题的缘故,在这个部分就只介绍一下他提取的特征吧。
文中使用了 6 种特征,3 种是 unlexicalized,另外 3 种则是 lexicalized。
Unlexicalized 的特征包括了:
- 计算 1-4 gram 的前提 (premise, 后文简写为 $p$) 和假设 (hypothesis, 后文简写为 $h$) 的 BLEU 分数
- $p$ 和 $h$ 的长度差
- $p$ 和 $h$ 的重复词的频率、概率,甚至还统计到了名词、动词、形容词和副词的层面上。
Lexicalized 的特征包括了:
- 统计了 $h$ 中 unigram 和 bigram 的指标
- 统计了 $p$ 和 $h$ 中共有的 POS 信息,包含 unigram 和 bigram 的。
作者还认为更复杂的模型可能会有更好的效果,于是就从 Sentence encoding-based 的思想出发,又做了一组实验。
Sentence encoding-based models
LSTM encoders
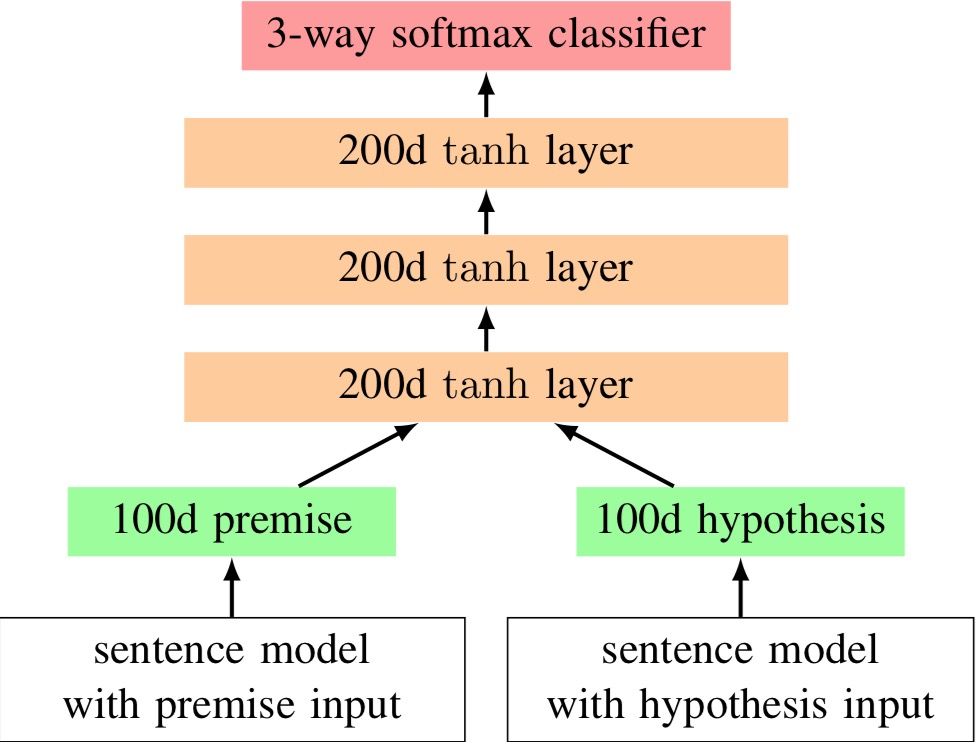
接着上一节的特征工程,Bowman 等人用 LSTM 来分别对 $h$ 和 $p$ 进行编码,之后再将输出丢到三层的带 tanh 激活函数的全连接层中,最后过一下 softmax 得到最终结果。模型架构很简单,毕竟这是 15 年的文章了,但还是有必要 show 一下,毕竟这是后续模型的雏形。
Tree-based CNN encoders
本来是不打算讲不同 encoder 的文章的 (比如 BiLSTM, GRU 之类的 encoder),不过这篇发表在 ACL2016 的 short paper 上的 TBCNN 还是挺值得一提的,因为他的拼接方法比较有意思,直接上图。
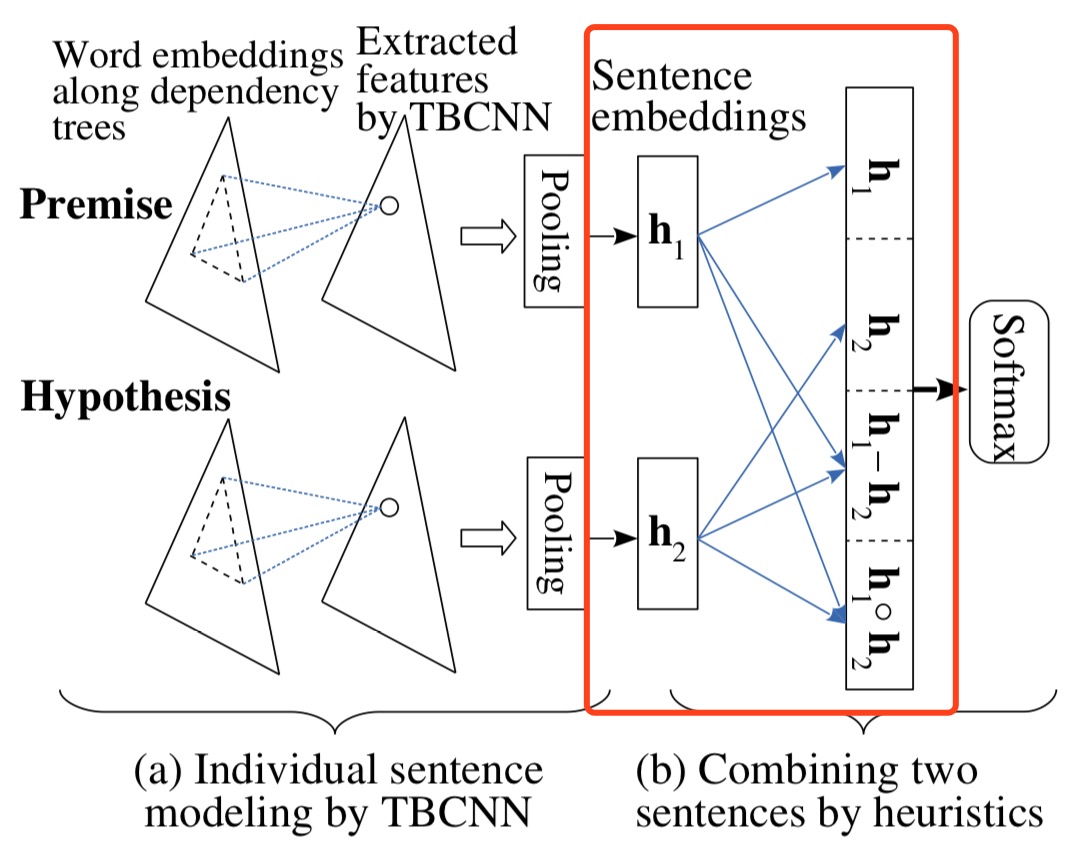
注意这里红框内的拼接部分,除了对 $p$ 和 $h$ 做简单的拼接之外,还做了 $p-h$,$p\cdot h$ 的操作,作者给出的解释是:
The latter two are certain measures of “similarity” or “closeness.”
于是最后拼接起来的向量为 $m = [p; h; p - h; p \cdot h]$。注意一下这个拼接方式,因为后续的很多模型最后都是用这种拼接方法的类似方法来做的,足以见得这种方法的有效性。
InferSent
这算是插播一条 InferSent 的介绍吧,InferSent 应该是目前最好的有监督 sentence embedding 的方法,它的出现改变了人们一贯认为的在 embedding 研究中,无监督是优于有监督的陈旧观点。
InferSent 模型出自 FAIR 发表在 EMNLP2017 上的 Supervised Learning of Universal Sentence Representations from Natural Language Inference Data。作者选用了 NLI 任务来进行有监督的句向量训练,原因是因为 NLI 任务本身的特殊性,它是涉及了句子内语义关系推导的高级自然语言理解任务,所以以这个任务为目标进行训练,可以产生较高质量的句向量表示。原文是这么写的:
We hypothesize that the suitability of NLI as a training task is caused by the fact that it is a high-level understanding task that involves reasoning about the semantic relationships within sentences.
InferSent 的模型图如下所示:
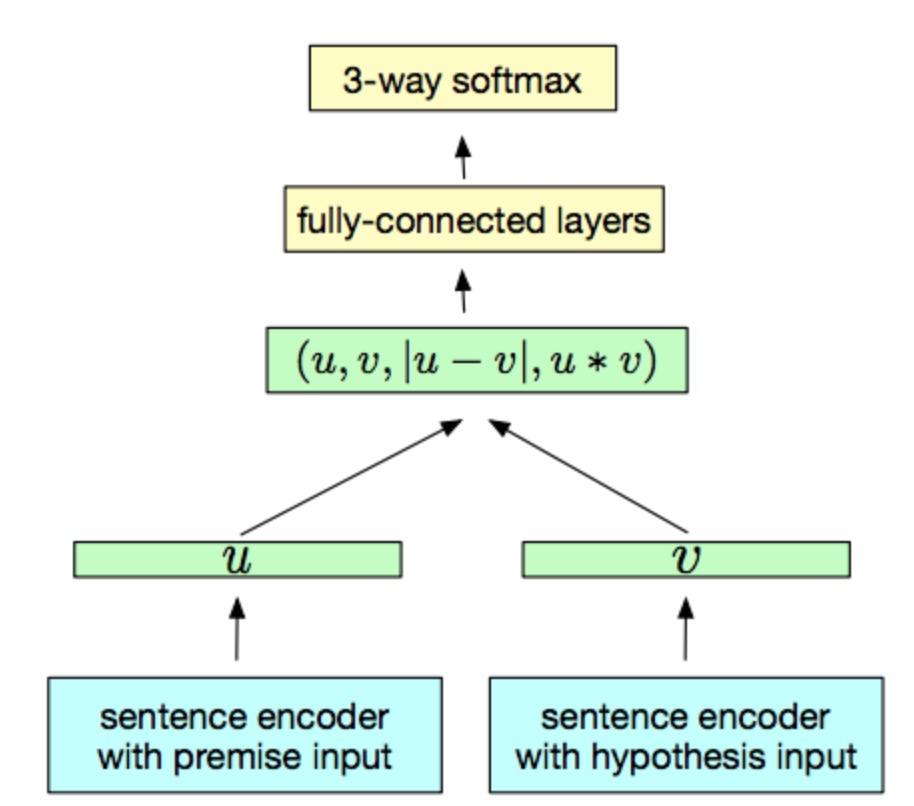
它的 sentence encoder 用的是 biLSTM,然后对 biLSTM 输出的隐藏状态按 timestep 轴做一个 max-pooling,理由是 biLSTM 这种双向 RNN 结构可以很好地结合上下文信息对单词进行再编码,之后的 max-pooling 则是保留了不同时刻中整个句子最重要的信息。然后就是上一小节所示的 $[u; v; |u - v|; u \cdot v]$ 的拼接形式 (注意这里使用的是绝对值求差,但本质上没什么区别,都是求前提和假设之间的线性相似度) ,最后接一下全连接层和 softmax。然后最终得到的 $u$ 和 $v$ 就可以作为该句子的句向量表示来使用在其他任务上了。模型很简单,但是取得了很好的效果。
最后附上我个人用 TensorFlow 复现的 InferSent 代码。
Structured Self Attention
讲了以上的 sentence embedding 的方法,这里顺道再讲一篇。
A Structured Self-Attentive Sentence Embedding 是发表在 ICLR2017 上的一篇文章,其本质上是对输入序列做 self-attention 操作,与普通 self-attention 不同的是,这篇文章的做法是将得到的 attention 权重扩展到了 $r$ 维,这样就得到了一个二维的句向量表示 $(r \times n)$。其实也就是将原本的 $(1 \times n)$ 的 attention 权重映射到了 $r$ 个不同的子空间上。
至于为什么要这么做,作者给出了解释:普通的 self-attention 会使得模型关注句子的一个特定的部分,也就是跟目标更加相关的单词或者短语的地方,希望通过突出这个部分来更好地表示这个句子的意思。然而,在很多情况下,尤其是遇到一个长句子的时候,句子中通常会有多个比较重要的部分,这时候你再只关注其中一块的话就有点不够用了,所以需要多个子空间才能够完整地表示整个句子的意思。
This vector representation usually focuses on a specific component of the sentence, like a special set of related words or phrases. So it is expected to reflect an aspect, or component of the semantics in a sentence. However, there can be multiple components in a sentence that together forms the overall semantics of the whole sentence, especially for long sentences. (For example, two clauses linked together by an ”and.”)
模型图如下所示:
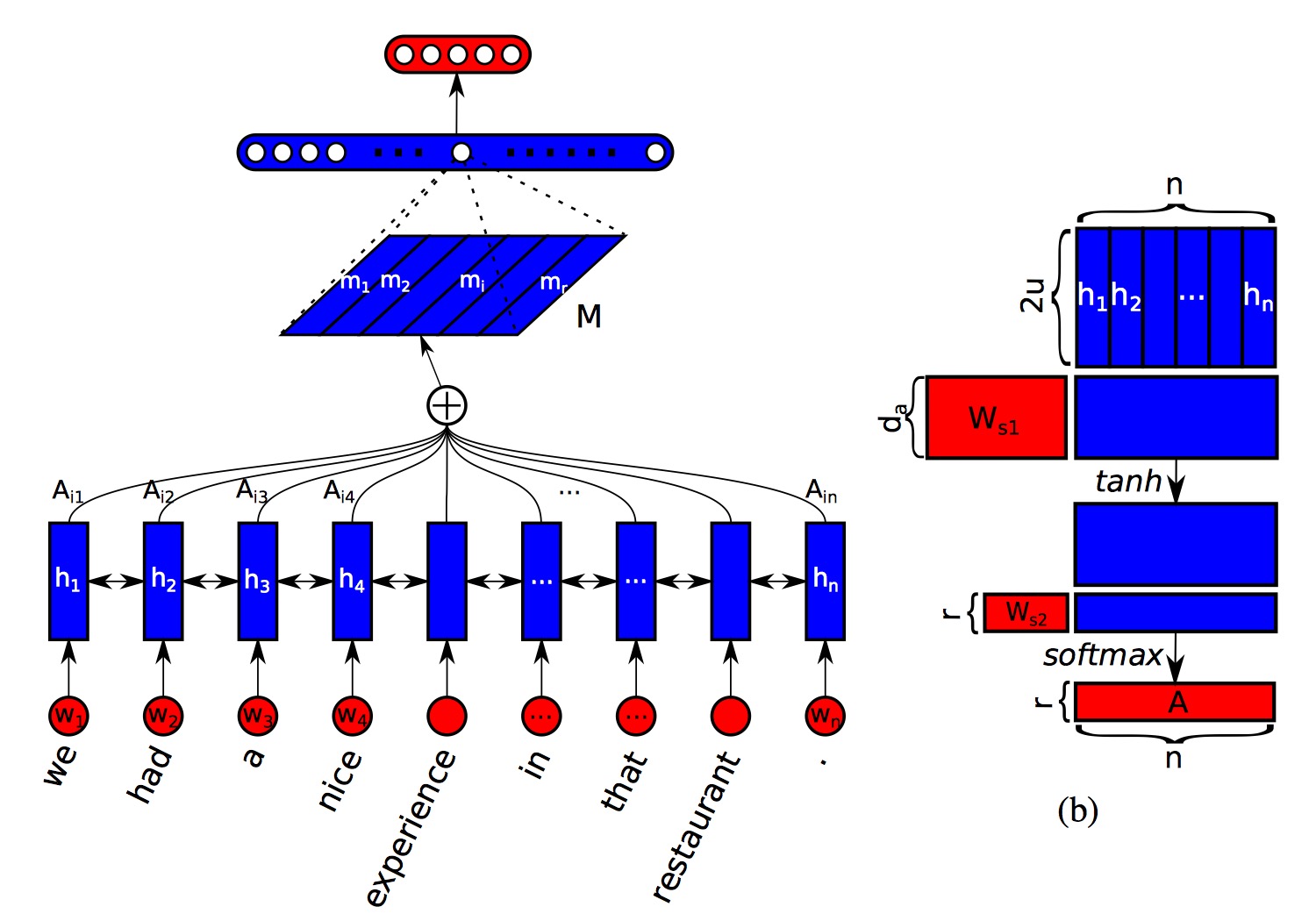
由图中可以看出来,前面部分都跟普通 self-attention 一样,只是最后通过 $W_{s2}$ 将 attention 权重映射成了一个$ (r * n)$ 的二维矩阵。其中 attention 权重矩阵 $A$ 和句向量的表示 $M$ 的计算公式分别为:$A = softmax(W_{s2}tanh(W_{s1}H^T))$,$M = AH$。
但是需要考虑的是,如果只是这么简单地映射到多维子空间去的话,很容易在不同维度的子空间中产生相同的表达,所以作者提出了一个解决办法,就是加上一个惩罚项 $P=||(AA^T-I)||_F^2$。
这个形式挺像 L2 正则项的,但是其中却大有玄机。很显然有 $0\le a_{i,j}=\sum_{k=1}^na_k^ia_k^j\le1$,当极端情况下,即 $a^i$ 和 $a^j$ 没有重叠的时候,$a_{i,j}$ 的值会为 0,当 $a^i$ 和 $a^j$ 的权重都偏向同一个词的时候,那他们的乘积 $a_{i,j}$ 就会趋近于 1。所以通过这个惩罚项,从对角线看,我们可以使得每个子空间上的 attention 权重集中在单个词上 (乘积趋近于 1);从对角线之外的项看,我们可以使得不同子空间上的 attention 权重尽量没有重合 (乘积趋近于 0)。这样的话就可以得到一个很完美的二维句向量表示了。
本文将这种 sentence embedding 的方法用在了 NLI 任务上来检验效果,模型图如下所示:
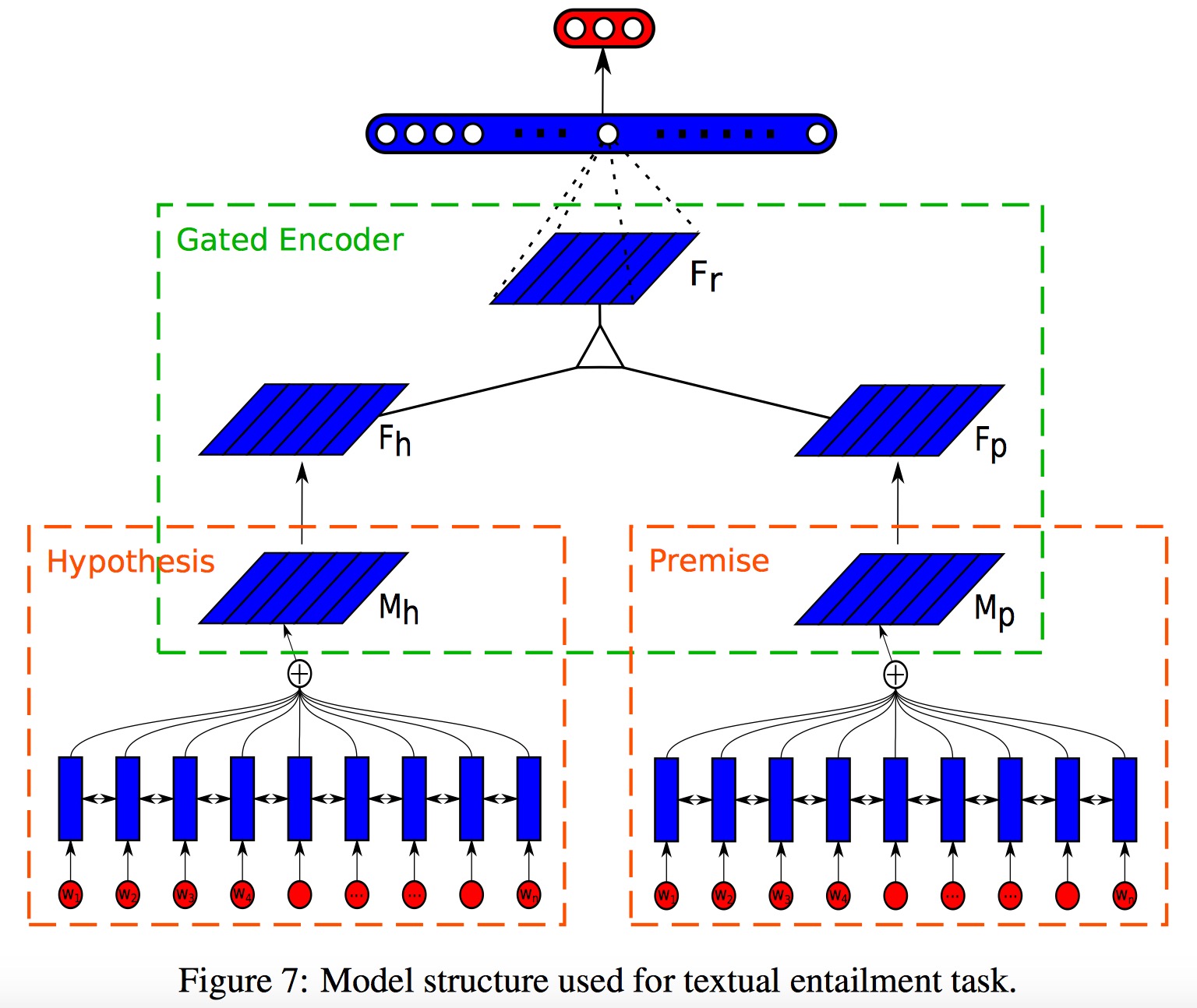
其实就是对 $p$ 和 $h$ 分别求一个二维的句向量表示 $M_p$ 和 $M_h$,然后再分别丢到全连接层得到 $F_p$ 和 $F_h$,接着对 $F_p$ 和 $F_h$ 做一下逐元素乘得到 $F_r$,最后再过一下 MLP 和 softmax 得到输出结果。
Other neural network models
mLSTM & word-by-word attention
mLSTM (match-LSTM) 在阅读理解上算是一个比较出名的模型了,与上面模型的做法不同的是,这篇文章是直接对 LSTM 单元动手脚。老实说这两个模型我就只跑过 mLSTM,并且这个模型跑起来的速度实在很慢,所以实际上我是直接放弃它了的节奏。
mLSTM 这篇文章是在 word-by-word attention 基础上进行的扩展,word-by-word attention 是出自发表在 ICLR2016 的 Reasoning about Entailment with Neural Attention 这篇文章里的,文章的做法是将 $p$ 和 $h$ 拼接起来,即用处理 $p$ 的 LSTM 状态来初始化 $h$ 的 LSTM 状态。文中还提出了个 word-by-word attention,在处理 $h$ 的每个词的时候,都引入 $p$ 的信息来计算,这种做法可以更好地发现 $p$ 和 $h$ 中词与词之间的关系。
而 mLSTM 这篇文章的作者认为 word-by-word attention 有两个不足:
- 仅使用了 $p$ 的单一向量来跟 $h$ 做匹配
- 没有对匹配和冲突这两种情况做区分
针对不足,mLSTM 对原模型进行了改进,他们直接把 attention 权重拼接到了 LSTM 的隐藏状态中去了,公式实在太多不想打了,直接截图附上好了。

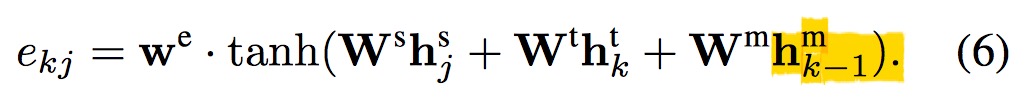
注意这 $h_j^s, h_k^t$分别表示 $p, h$ 的隐藏状态。
文中在实验细节部分还说了一下他们用的一个 trick,即他们在 $p$ 中引入了一个特别的词 NULL (用向量 $h_0^s$ 表示),在做匹配计算的时候,如果 $h$ 找不到跟 $p$ 相匹配的词的话,就会对齐到这个 NULL 上来,这样就增加了悬空对齐的方式,完善了对齐模型。
Decomposable Attention
终于轮到了在 NLI 领域大名鼎鼎的 Decomposable Attention 了,这也是我非常喜欢的一篇文章。这篇文章全名是 A Decomposable Attention Model for Natural Language Inference,是 Google 那帮大佬发表在 EMNLP2016 的一篇文章。
文章开头先给出了个例子:
- Bob is in his room, but because of the thunder and lightning outside, he cannot sleep.
- Bob is awake.
- It is sunny outside.
我们以第一个句子作为前提,第二、三个句子作为假设。我们发现第一个句子有个 cannot sleep,第二个句子有个 awake,他们是一组同义词,很好,那么一二句的关系就可能是蕴含关系了。再看第一个句子中的 thunder and lightning 和第三个句子中的 sunny,很明显这两个词是不相符的啊,所以一三句的关系就很可能是矛盾的了。
出于这种思想,Google 这帮大佬们认为,其实我们直接把原问题分解开,看成一个个单词间的对齐问题不就完事儿了?大道至简。
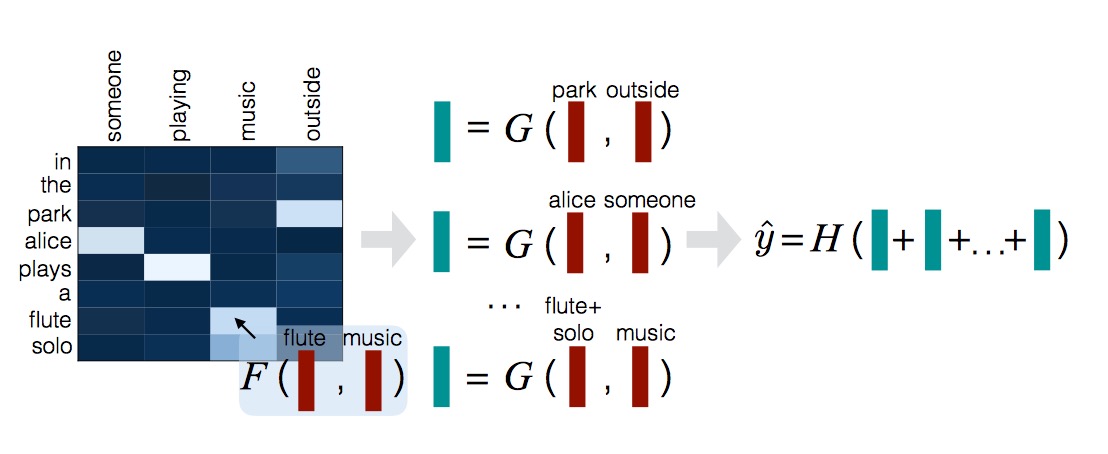
模型分为三步:
- 对 $p$ 和 $h$ 分别过一下一个共用两层的带 relu 激活函数的前馈神经网络 F,并各自计算 attention 权重 (其中 $\bar a,\bar b$ 为单词的词向量表示)
- $e_{ij}=F’(\bar a_i, \bar b_j)=F(\bar a_i)^T F(\bar b_j)$
- $\beta_i=\sum_{j=1}^{l_b}\frac{exp(e_{ij})}{\sum_{k=1}^{l_b}exp(e_{ik})}\bar b_j$
- $\alpha_j = \sum_{i=1}^{l_a}\frac{exp(e_{ij})}{\sum_{k=1}^{l_a}exp(e_{kj})}\bar a_i$
- 将 attention 权重和原本的输入变换拼接起来做对齐操作,G 同样为共用的两层带 relu 激活函数的前馈神经网络
- $v_{1,i}=G([\bar a_i, \beta_i])$
- $v_{2,j}=G([\bar b_j, \alpha_j])$
- 将对齐后的向量求和并拼接起来,放入前馈神经网络 H 中
- $v_1 = \sum_{i=1}^{l_a}v_{1,i}$
- $v_2 = \sum_{j=1}^{l_b}v_{2,j}$
- $\hat y = H([v_1,v_2])$
最后文章又补充了一种 Intra-Sentence Attention 的做法。在计算 $\bar a$ 的时候加入了 attention,令 $f_{i,j}=F_{intra}(a_i)^TF_{intra}(a_j)$, $a’i=\sum{j=1}^{l_a}\frac{exp(f_{ij}+d_{i-j})}{\sum_{k=1}^{l_a}exp(f_{ik}+d_{i-k})}$,其中 $d$ 为两个词之间的距离。这样得到 $a^{‘}_i$ 后令 $\bar a=[a_i, a^{‘}_i]$ ,$\bar b$ 也做同样的操作,后续的处理过程跟上述一样。
Decomposable Attention 算是走了一种极端,把原问题简化成单词间的对齐问题,连 RNN 单元都没有用上,而是直接拿预训练得到的词向量做操作,这样难免会损失掉一些上下文信息。不过这种精神还是很值得学习的,在大家都在堆模型的时候,它另辟蹊径地走出了这么一条路来,即将原问题分解为单词间的对齐问题,这也为后续的很多研究奠定了基础。
因为很喜欢这篇文章,我也用 TensorFlow 实现了一下 Decomposable Attention 的代码。
ESIM
ESIM 模型算是 NLI 领域未来几年一个很难绕过的超强 baseline 了,单模型的效果可以达到 88.0% 的 Acc,简直吊打一帮人。
ESIM 模型出自 Qian Chen 等人发表在 ACL2017 上的 Enhanced LSTM for Natural Language Inference。也算是对 Decomposable Attention 的一个改进,然后它还加入了句法信息,组成了 HIM 模型,这种思想也为 NLI 后续的研究提供了一个思路。模型图如下所示:
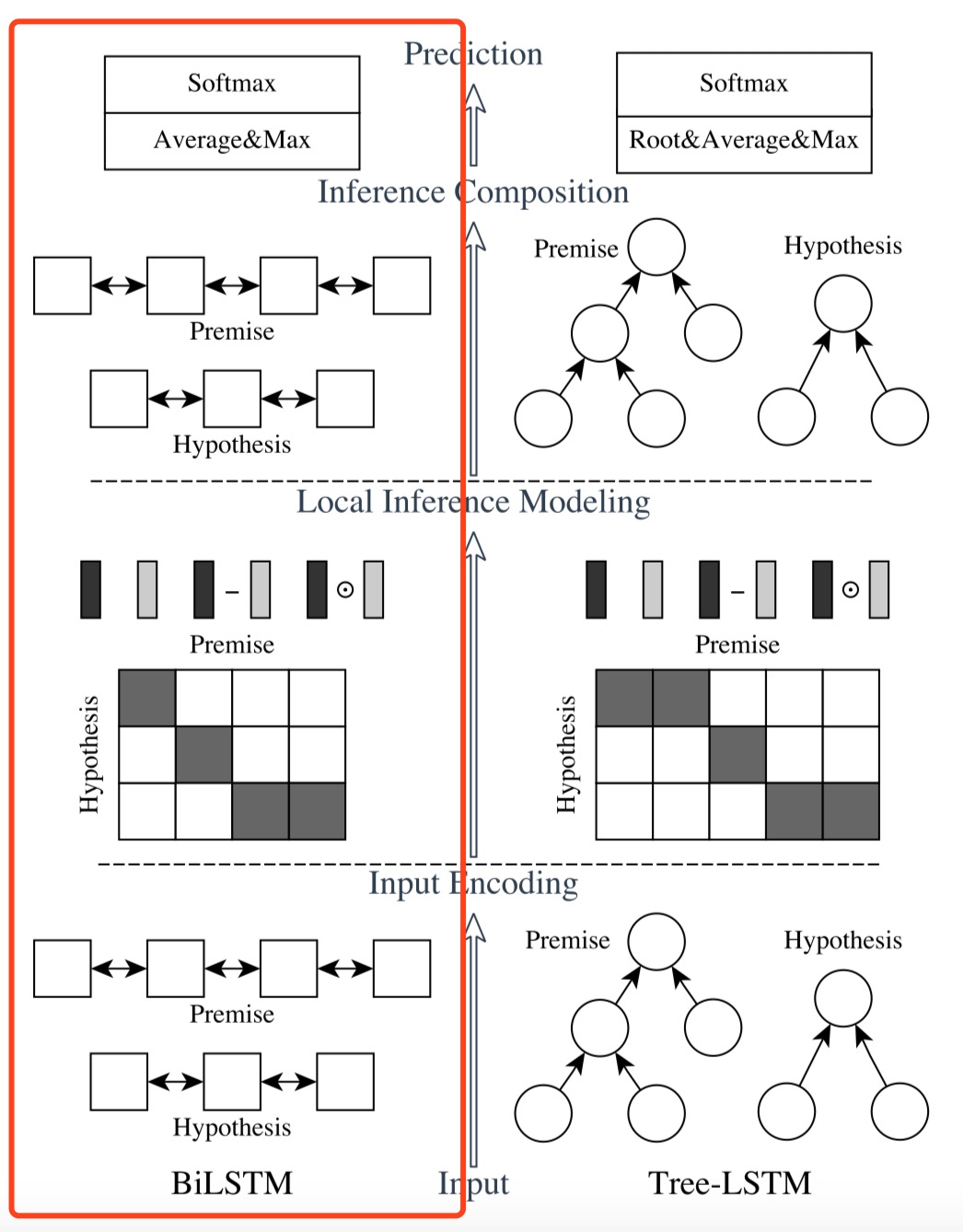
其中左边红框部分就是 ESIM 模型,整体结合起来则是 KIM 模型。
上一节提到,Decomposable Attention 在输入编码时候是直接用前馈神经网络对预训练的词向量做操作,这样会损失掉一些上下文信息。而 ESIM 则在输入和最后的拼接部分对其做了改进,模型分为三步:
- [Input Encoding] 使用复用的 biLSTM 单元分别对 $p$ 和 $h$ 进行编码,得到 $\bar a, \bar b$
- [Local Inference Modeling] 使用 Decomposable Attention 分别对 $p$ 和 $h$ 做权重计算,得到 attention 权重 $\hat a, \hat b$
- [Inference Composition] 分别对 $p$ 和 $h$ 进行拼接 (看形式是不是跟上文的 Tree-based CNN 一个套路?),最后做一个求最大值和均值的操作再将 $p, h$ 拼接起来,过一下biLSTM、FFN 和 softmax 得到最终结果
- $m_a=[\bar a;\hat a;\bar a- \hat a; \bar a\cdot\hat a],m_b=[\bar b;\hat b;\bar b-\hat b;\bar b\cdot \hat b]$
- $v_{a,ave}=\sum_{i=1}^{l_a}\frac{v_{a,i}}{l_a},v_{a,max}=max_{i=1}^{l_a}v_{a,i}$
- $v_{b,ave}=\sum_{j=1}^{l_b}\frac{v_{b,j}}{l_b},v_{b,max}=max_{j=1}^{l_b}v_{b,j}$
- $v=[v_{a,ave};v_{a,max};v_{b,ave};v_{b,max}]$
这就是 ESIM 的模型结构了。除此之外,文中还考虑了加入一些其他的信息,比如 Parsing。文章直接使用了一个 Tree-LSTM 来提取句法信息,除了 encoder 外其他部分的处理跟 ESIM 类似,所以不赘述了。这两个模型合并起来就凑成了 HIM 模型,最终达到了 88.6% 的 Acc。
ESIM 这个模型实在太过于经典,我在携程的矛盾数据集上也想使用这个模型,所以自己也用 TensorFlow 实现了一遍 ESIM 的代码。
KIM & DMAN
这两篇是都是出自 ACL2018 的文章,HIM 模型用到了句法信息,启发了一下后续工作的思路,即添加一些外部信息,这两篇 ACL18 的文章正是沿着此路一直走下去的。
首先是 KIM,出自 Neural Natural Language Inference Models Enhanced with External Knowledge,模型上和 ESIM 大同小异。这篇文章加入的是词汇语义关系的信息,比如同义词、反义词、上位词、下位词、同下位词。通过赋予他们不同的权重,在最后拼接的步骤将他们拼接到末尾,得到 KIM 模型,最终跟 HIM 一样取得了 88.6% 的 Acc。
然后是 DMAN,出自 Discourse Marker Augmented Network with Reinforcement Learning for Natural Language Inference。这篇文章有点耍杂技的味道,在输入端很丧心病狂地将 Word Embedding, Char Embedding, POS, NER, Exact Match 信息拼接起来使用,随后又先用增强学习做一下 DMP (Discourse Marker Prediction) 任务,然后用迁移学习的思想将得到的模型参数拿过来这边使用,以获取句子表示,最后再过一个交互层将 biLSTM 的输出和句子的表示进行交互。。。
我知道我这么说很多人都受不了了,但它模型的确是这样子的,我看的时候也很崩溃。
老实说我很讨厌这种类型的文章,个人觉得除了刷分外真的没有太大的意义。
DIY
看了那么多论文和模型,当然自己也得 DIY 一个才算过瘾了啊。
- 首先就是输入端的编码,biLSTM 单元确实能够更好地保留句子中单词的上下文信息,所以一开始我就直接很常规地使用复用的 biLSTM 分别对 $p$ 和 $h$ 进行编码。
- 考虑到 structured self attention 确实能够更好地对句子进行表示,所以我直接将 biLSTM 的输出丢入到 structured self attention 中去,得到 $p$ 和 $h$ 的二维矩阵。虽然原文说的是得到句向量的二维表示,但是由于其惩罚函数的缘故,不同子空间的 attention 权重会更加集中于不同的单词上,所以我们可以把它理解为经过了一层 self attention 变换后, $p$ 和 $h$ 保留下来了它们最重要的几个单词的信息。
- 接下来就到了 decomposable attention 的 showtime 了,将问题再化为 $p$ 和 $h$ 的几个关键单词的对齐问题。最终得到它们对齐后的 attention 权重向量。
- 最后就是拼接的模块了,既然前人们经过了无数实验试出来了上述的那套拼接方法,那我就拿来直接套用了。具体步骤可以参考 ESIM,不过我把它最后的那步 biLSTM 去掉了,因为我认为对于对齐后的信息再来做 biLSTM 并没有多少意义。
随手用 keynote 画了个简单的模型图如下 (先凑合着吧,虽然确实难看了点,如果哪天要投稿了再来改好了)
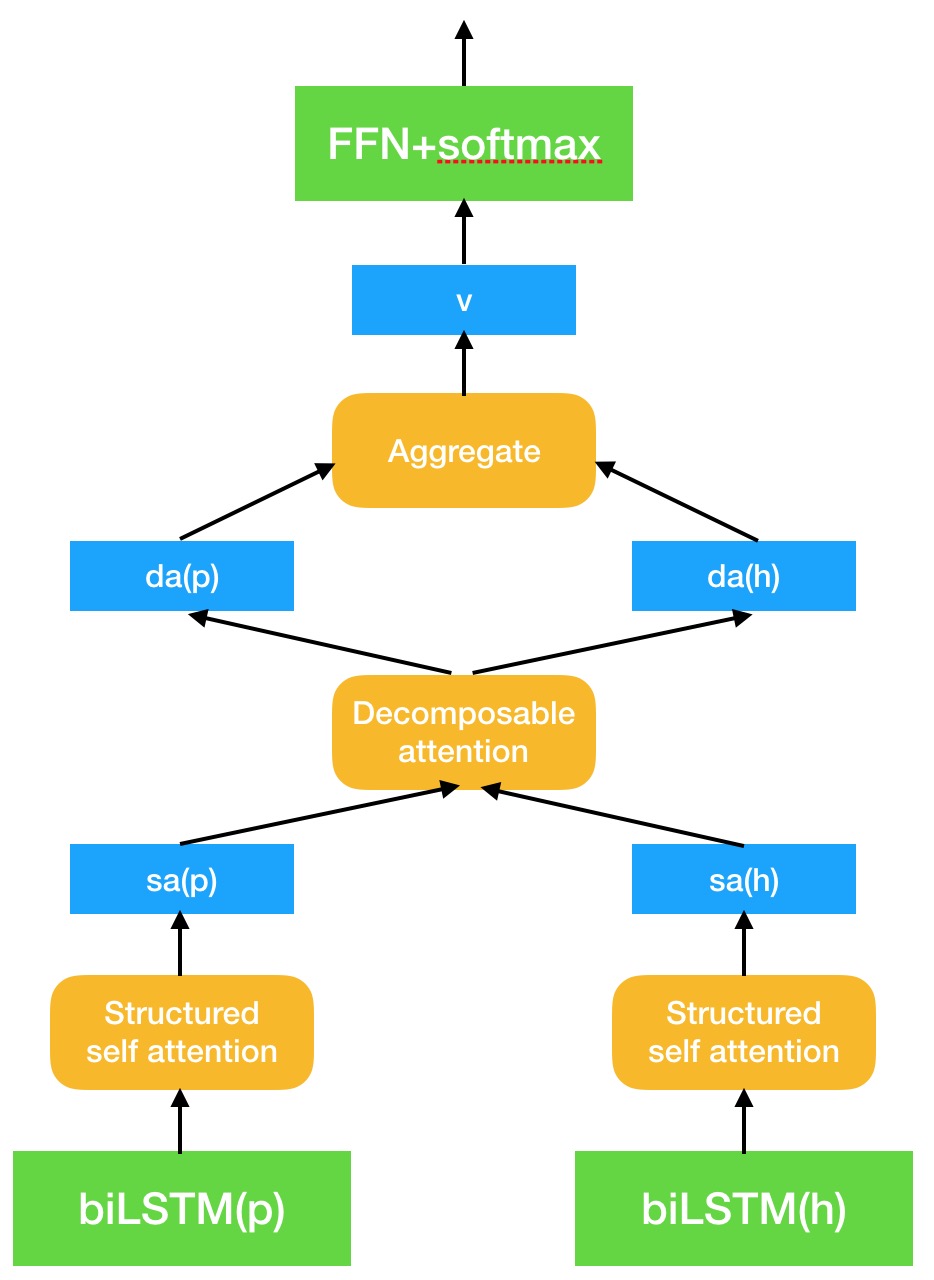
DIY 模型的代码也放在了 GitHub 上面了,然而现在由于并没有机器,只能等其他模型训练完了后再来试试我这个模型在标准数据集上的结果如何了。希望能够跑个不错的结果出来,借机水一篇文章。 _(:з」∠)_
模型落地
说了这么多,事实上项目中实际上上述所提及的模型都没有用到 (笑),而是使用了一个我 DIY 模型的简化版本。
因为这个项目其实只需要判断一下两个条款是否矛盾就可以了,而不用考虑其蕴含关系。而对于矛盾的判断并不像蕴含关系那样,我个人认为只要关注前提与假设的个别单词间的关系就足够了,因而像 ESIM 后面的那个 biLSTM 在这个项目中的意义实在不大。事实上在携程的真实数据集中,DIY 模型的简化版本确实在精度和速度上都优于 ESIM。
然而这些数据还是有一些问题的,条款中会出现诸如以下的这类矛盾:
- A:8 岁以上儿童必须占床;B:2-10 岁儿童可以自行选择是否占床。
- A:请于起飞前 120 分钟到达机场;B:请于起飞前 150 分钟到达机场。
像 1. 2. 这类包含数字的矛盾,想让模型判断对真的很难,所以之前携程一直都是使用规则来进行矛盾条款判断。然而规则做法随着商品越来越多,情况越来越复杂,为了保证精度,只能让规则越来越复杂,越来越“过拟合”。可等新的商品一上线又容易引出一堆问题,又陷入重新修改规则的循环中。
本着自己花那么多时间搞出来的东西不上线就亏了的心态,我提议让 leader 把规则给设得严格一点,把准确率给做上去,不管召回率如何。通过规则先去判断出那些模型很难分析出来的矛盾问题,然后再把被规则判定为不矛盾的条款丢给模型进行判断,这样的话就可以在保证精度的前提下,把我的模型给上上去啦,而且也不用三天两头地改规则了。
这是我写的第二篇总结性质的文章,也是我对于这将近一个月的实习经历的总结。之后这个项目应该算是告一段落了吧,因为 leader 说接下来准备让我做情感分析的任务去了。
参考文献
- The Stanford Natural Language Processing Group
- A large annotated corpus for learning natural language inference
- Natural Language Inference by Tree-Based Convolution and Heuristic Matching
- Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
- A Structured Self-Attentive Sentence Embedding
- Reasoning about Entailment with Neural Attention
- Learning Natural Language Inference with LSTM
- A Decomposable Attention Model for Natural Language Inference
- Enhanced LSTM for Natural Language Inference
- Neural Natural Language Inference Models Enhanced with External Knowledge
- Discourse Marker Augmented Network with Reinforcement Learning for Natural Language Inference


