本文是 FAIR 在 ACL17 上面的一篇文章。目的是为了解决 NLP 中常见的文本分类问题,并且能够产生词向量作为副产物。
本文提出了大名鼎鼎的 fastText 工具,训练速度很快,而且效果可以跟深度神经网络相当。
本文的作者是 Mikolov,即也是 Word2Vec 的作者,这篇文章在模型架构上跟 Word2Vec 很相似,因为之前已经有详细写过 Word2Vec ,在此就简单说一下他们的区别。
模型架构
本篇文章的方法部分大概可以分为三块 (虽然按标题看只有两段):fastText 模型架构、Hierarchical softmax、N-gram features。
fastText 模型架构
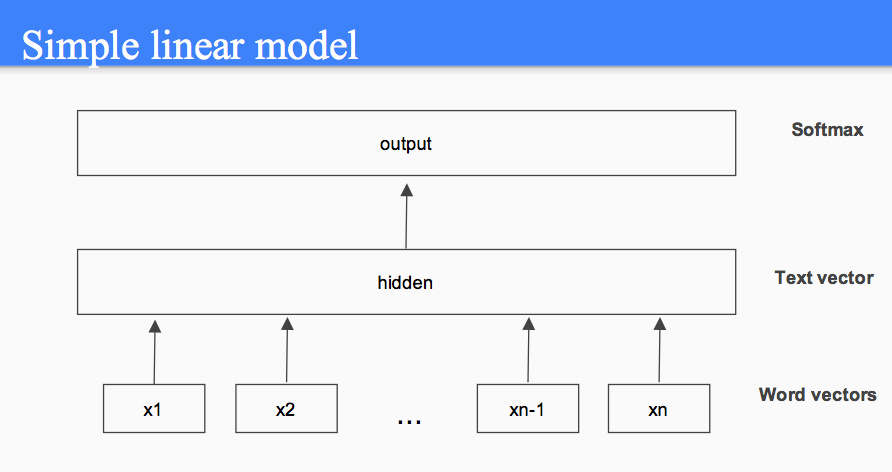
fastText 的模型架构部分跟 CBOW 很相似,这里直接说区别:
| 区别 | CBOW | fastText |
|---|---|---|
| 输入 | 中心词的上下文 | 多个单词及 n-gram 特征 |
| 编码方式 | One-hot | Embedding |
| 输出 | 中心词 | 文档类别 |
fastText 的核心思想:将整篇文档的词及 n-gram 向量叠加平均得到文档向量,然后用 hierarchical softmax 做分类。
Hierarchical softmax
其实这块没什么好说的,只是把 CBOW 进行的输出端中心词分类换成了对于文档的分类,依照文档的类别建 huffman 树。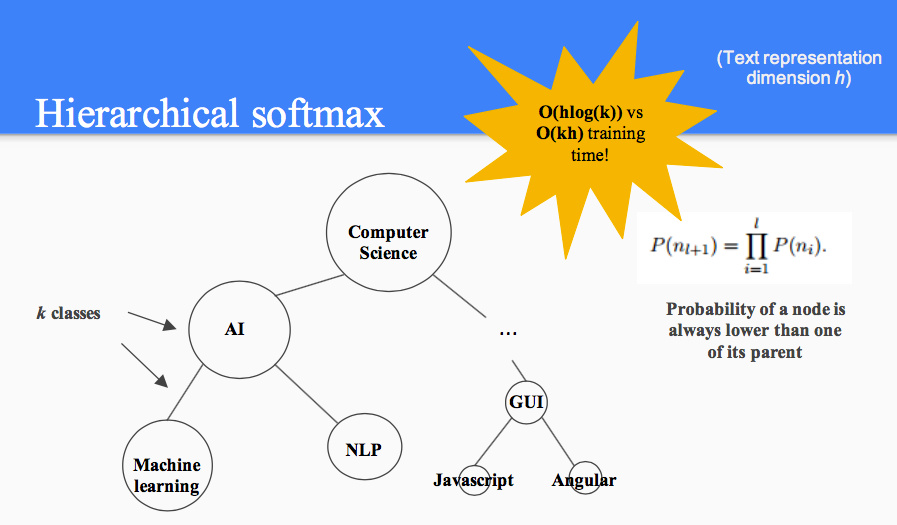
N-gram features
这块其实是一种很常见的方法,我们知道预训练所得的词向量是固定的,这在于文本分类的任务中,将会丢失一些句子 \ 文档环境中的上下文信息。于是思路就很自然地想到了用 N-gram 的方法来捕获一些上下文信息。
这里需要提及的是本文中使用的 n-gram 是词级别的,举个例子:
关于句子 “Bag of Tricks for Efficient Text Classification”,假设 n 取 3,则整个句子就变为 (“Bag of”, “Bag of Tricks”, “of Tricks for”, “Tricks for Efficient”, …)。
结果
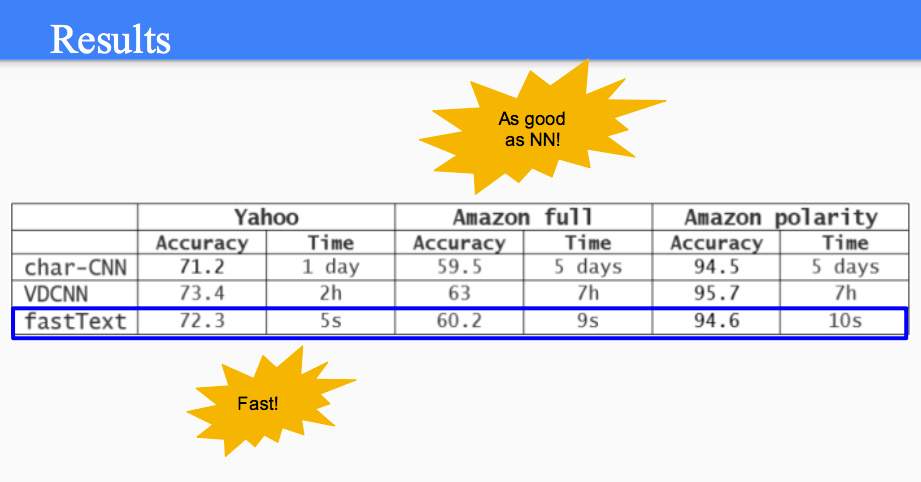
直接上图,效果不错。fastText 宣扬了一下奥卡姆剃刀的思想,“杀鸡焉用牛刀”。不过得注意一下,fastText 的输入是 embedding 后的词向量,本身就包含了单词的相似度、语义、语法信息,这是其除了 N-gram 外提升精度的另一个原因。
本文其实并没有太多好讲的地方,不过跟其同阶段提出的 Enriching Word Vectors with Subword Information 很值得学习,这篇文章我在 A review on word embedding 进行了介绍。


